Backup model
This article describes the algorithm behind the backup model.
CodeTwo Backup is an incremental backup software solution designed for both Microsoft 365 (including SharePoint Online) and on-premises Exchange Server. Incremental backup means that only the initial cycle of a backup job backs up the entire mailbox or SharePoint Online site content. Subsequent cycles are incremental, i.e. the software queries your Exchange or SharePoint environments for changes in the desired mailbox/site since the previous cycle. If any changes are detected, only the modified or new items are backed up again. The software does not back up the unmodified items again. This solution speeds up the whole process and saves disk space.
Additionally, CodeTwo Backup features item versioning. If during consecutive job cycles the software detects that the backed-up content was changed, the modified items are backed up again and stored together with the previous versions of the same items (older item versions are not overwritten). As illustrated in Fig. 1., unchanged items are not unnecessarily duplicated during cycles #2 and #3 - only new items are backed up in cycle #3. During cycle #4, a changed item is versioned to allow for restoring of the older copy in the future. Thanks to this approach, during a restore job the user of the software is able to restore not only the most recent local copy of an item but any previous version of it (assuming of course that there was more than one job cycle since the creation of this particular item).
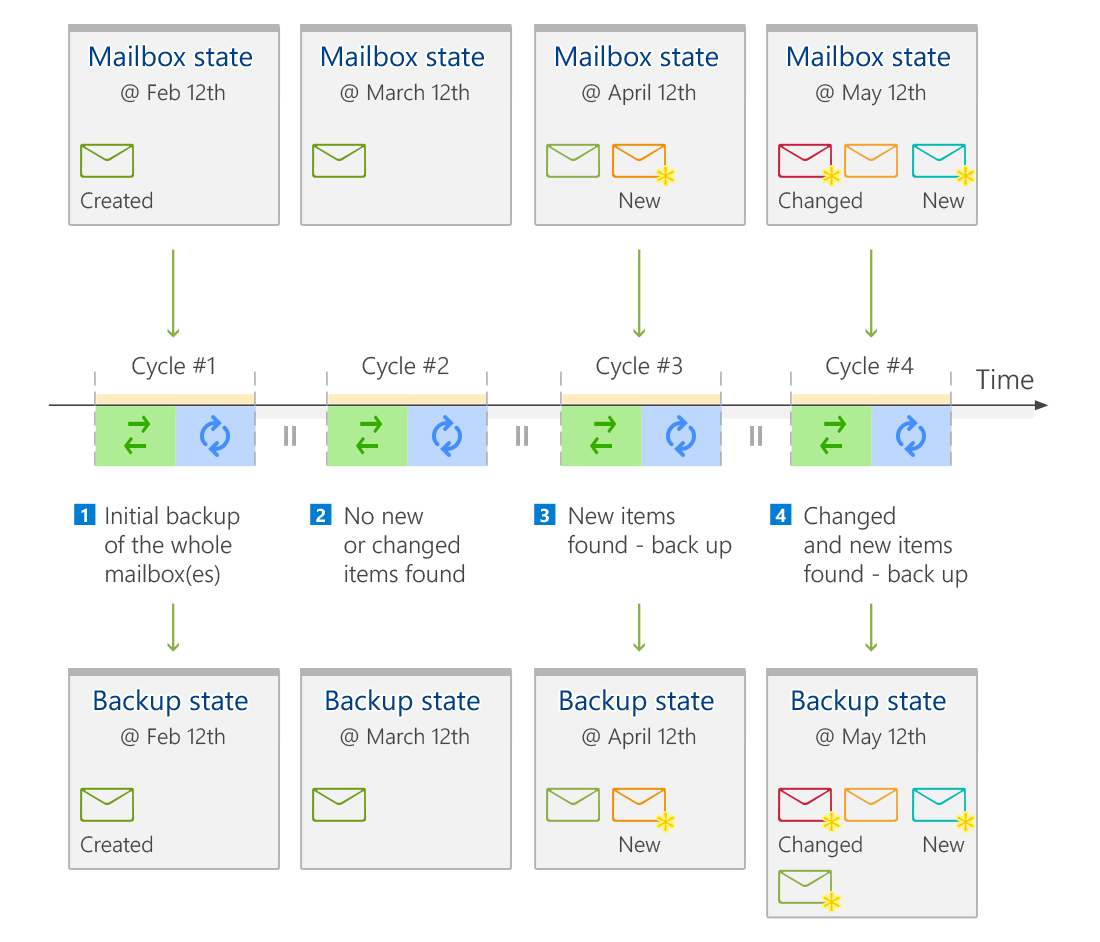
Fig. 1. Incremental backup and items versioning in CodeTwo Backup.
Moreover, if you have enabled versioning for a SharePoint Online library, each backed-up library item (e.g. a Word document) will also contain all SharePoint versions of such an item (Fig. 2).
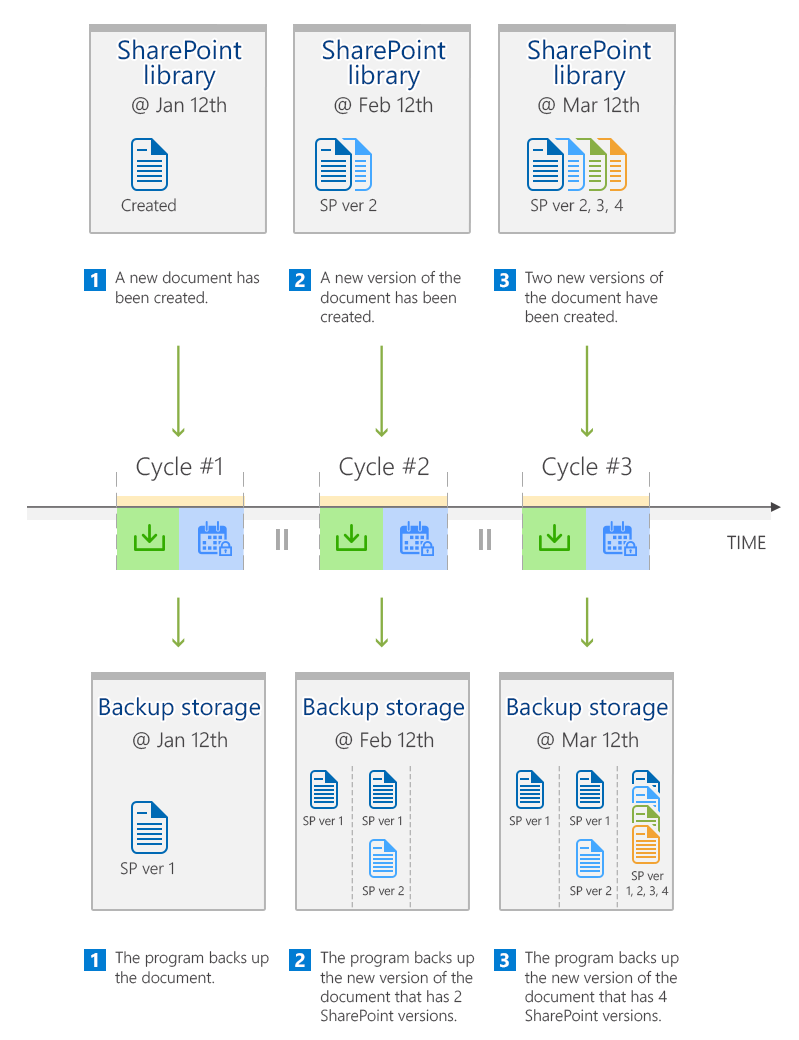
Fig. 2. Backup of SharePoint library items in CodeTwo Backup.
The backed-up data is kept encrypted in a user-defined local drive location known as storage. The software user can configure multiple storages which can be either shared between multiple jobs or used exclusively by one job.
Backup jobs are what defines the scope of the backed up data. Similarly to storages, users can configure many jobs (backup, restore, or archive) to, for example, cover different sets of mailboxes, item types, the age of backed up items, and so on (Fig. 3.).
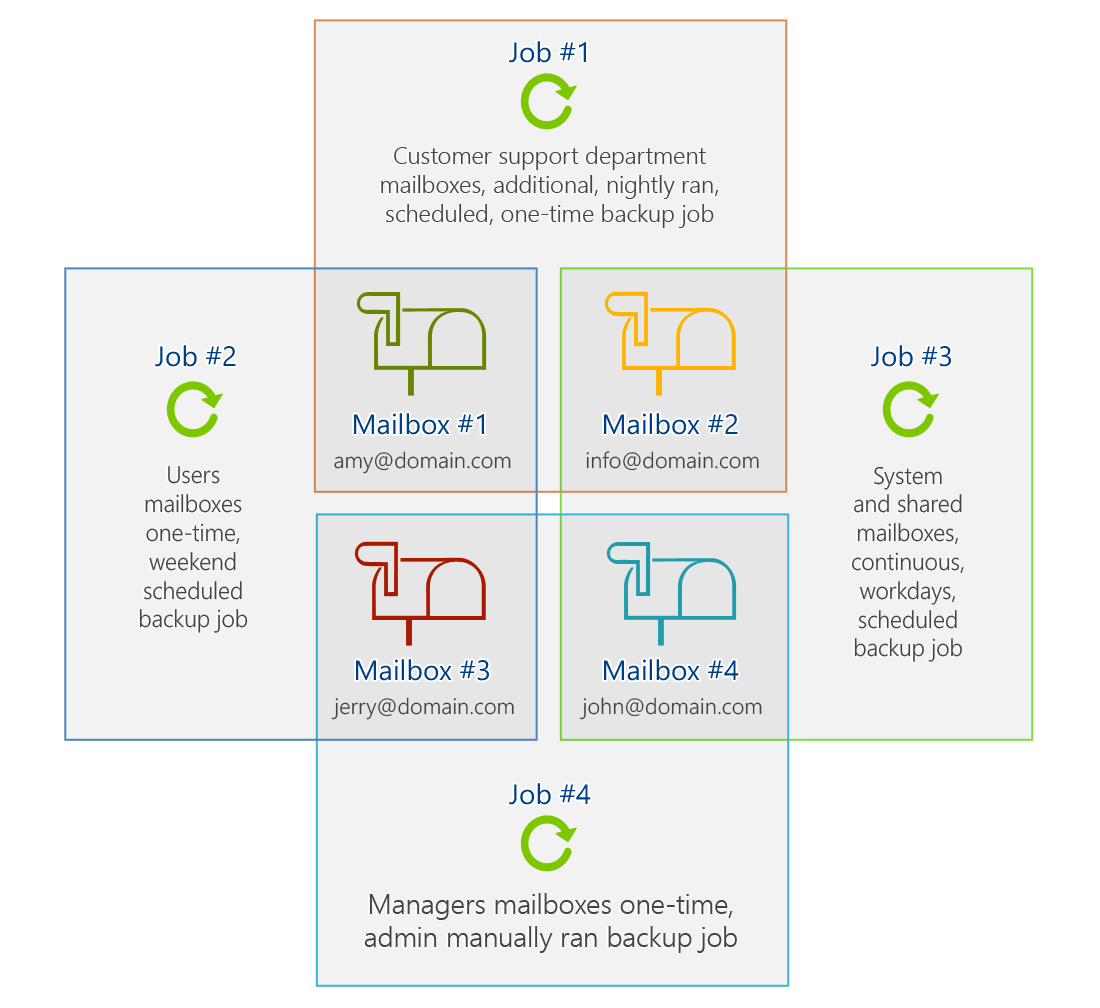
Fig. 3. Example of converging backup jobs.
Jobs run in cycles which consist of two phases: comparison and actual backup. In the case of Exchange backup jobs, during the first phase, the software communicates with the source server’s Exchange Web Services asking for the mailboxes’ folders and items' hashes. Those are compared to previously saved hashes to find out whether there were any changes in the mailbox or not. If the mailbox content changed since the previous cycle, the actual backup process starts.
Backup jobs can be divided into two types based on their continuity profile. There is the one-time backup (Fig. 4.) that backs up all user-specified mailboxes or sites only once and then stops, and there is the continuous backup (Fig. 5.) which runs constantly: the software backs up mailboxes and site and, once finished, it starts all over again. To avoid excessively frequent backups in this mode, the user can define the so-called idle time in the backup job configuration wizard. This is the break the software will take before starting another cycle of a continuous backup.

Fig. 4. One-time backup explained.
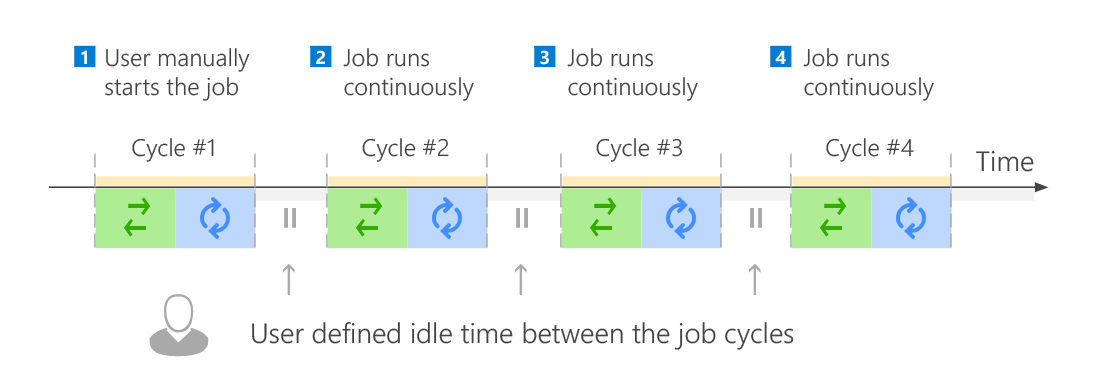
Fig. 5. Continuous backup explained - note the repeated cycles and idle times.
Moreover, the program features a built-in scheduler which allows the software's user to customize job's activity periods even more (Fig. 6. and 7.). The scheduler can be configured separately for each job, for example to run one-time backup jobs of all mailboxes only on weekends and continuous backup jobs of the most important mailboxes during the working hours. Please note that the scheduler will automatically start a job at the beginning of a defined activity period, which makes the backup process seamless and fully automated.
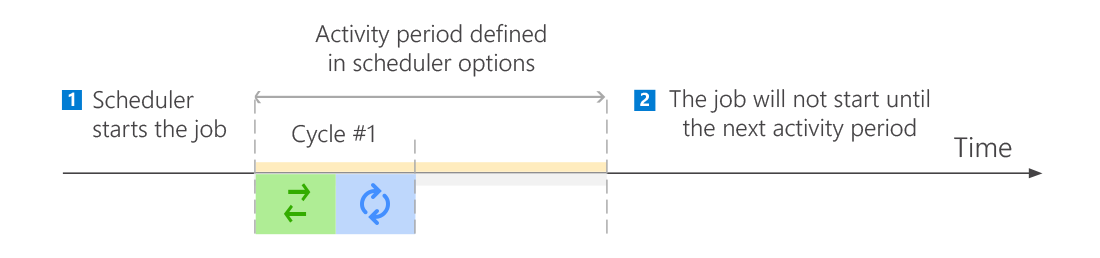
Fig. 6. One-time backup run by the scheduler within a defined activity period.
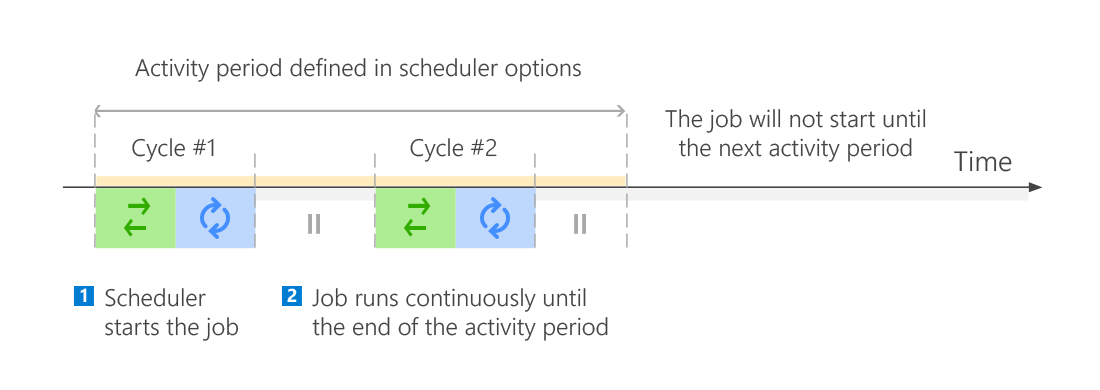
Fig. 7. Continuous backup execution by the scheduler during an activity period.
See also
Creating backups - this article describes all there is to know to create new backup jobs.
In this article