Configuring an archive job
This article explains how to configure an archive job for a selected storage.
Start by opening the archive job wizard. You can do it:
- from the Jobs tab, by clicking New > Archive storage on the top menu (Fig. 1.),
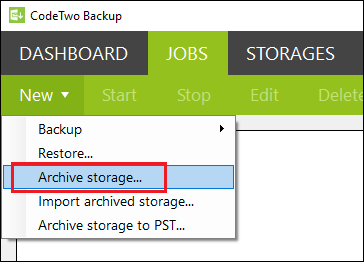
Fig. 1. Creating a new archive job from the Jobs tab.
- or you can go to the Storages tab and either select a storage and then click the Archive button on the top menu, or right-click the storage and choose Archive from the shortcut menu (Fig. 2.).
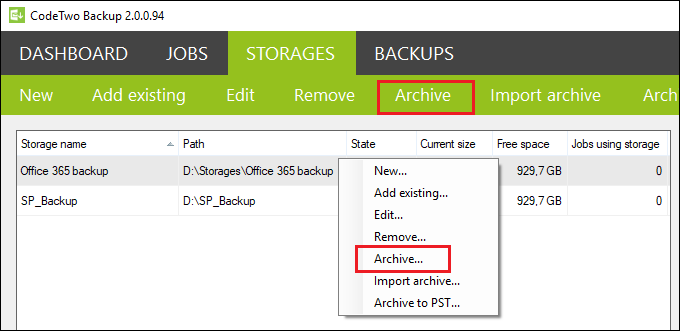
Fig. 2. Creating a new archive job from the Storages tab.
Either way, the New archive job wizard will open (Fig. 3.). The wizard consists of the following steps that will guide you through the configuration of the archive job:
- Job name, where you define the name of the archive job.
- Source storage, where you select the storage and data type (Exchange/SharePoint) you want to archive.
- Target archive, where you choose the location where the archive will be saved.
- Archive retention, where you define a retention policy for the archived data.
- Scheduler, where you can specify when the archive job should automatically start.
- Password, where you can password protect your archive.
- Recovery key, where you can save a key that can be used to recover your data.
- Job summary, where you can review your archive job settings.
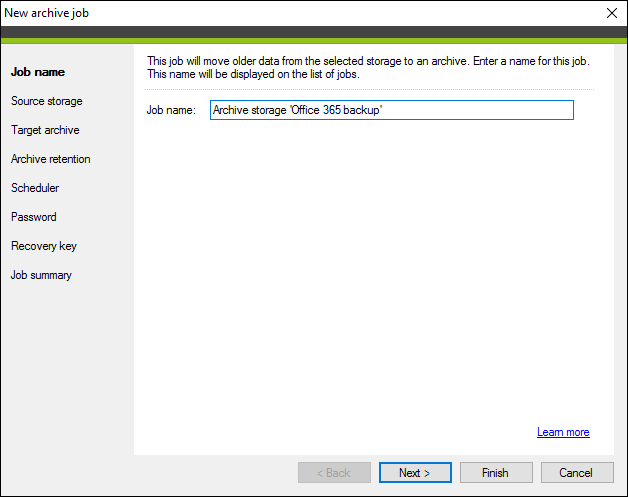
Fig. 3. The archive job wizard.
Job name
In the first step of the wizard (see Fig. 3. above), provide a unique name for the archive job. By default, if you start the wizard by selecting a specific storage on the Storages tab, the program will name the Job name field according to the following pattern:
Archive storage '[storage name]'
You can change the default name, for example, if you plan to archive the same storage in the future but to another location or by using different settings. You cannot create two jobs with the same name.
Source storage
First, select a storage from the drop-down menu (Fig. 4.).
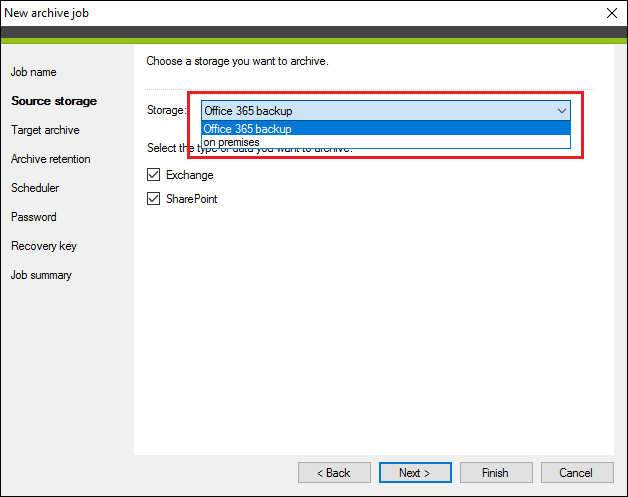
Fig. 4. Selecting storage to be archived.
Next, mark the checkbox next to the data type you want to archive from that storage: Exchange or SharePoint (Fig. 5.). You can choose to archive only Exchange data (user mailboxes, public folders, etc.), only SharePoint data (site collections, team sites, OneDrive sites), or both.
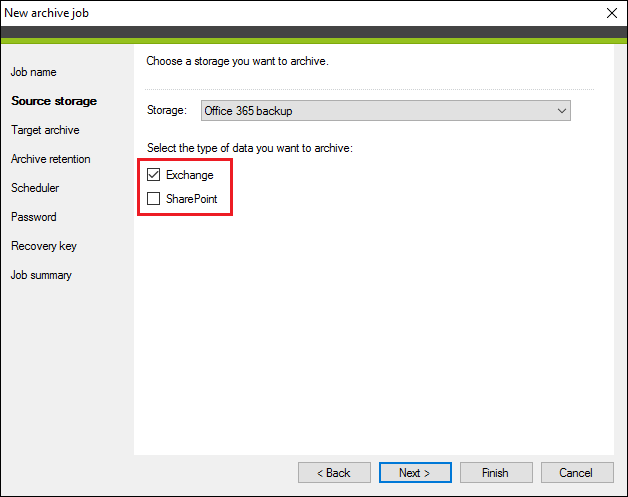
Fig. 5. Selecting the type of data to be archived.
Important
SharePoint site mailboxes are part of the Exchange data. In order to archive the SharePoint site mailboxes data, make sure to select to archive Exchange data as well.
Note that the program will archive the entire content of the selected storage, including data backed up from on-premises environments (Exchange Server or SharePoint Server) as well as from Microsoft 365 (Office 365). There is no option to archive individual mailboxes, sites, folders, or files. This means that all items, including all their versions, as well as the entire folder structure, will be copied to the archive.
Target archive
Click the Browse button and select the folder (or create a new one) where you want to archive your storage (Fig. 6.). It’s not possible to use the same folder to archive two or more storages. You also cannot create archives on a mapped network drive.
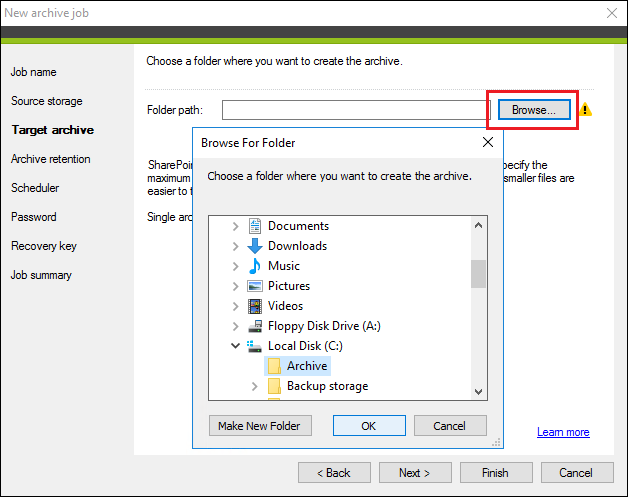
Fig. 6. Selecting a folder to save an archive.
Exchange data, when being archived, is divided into folders and subfolders that resemble a mailbox folder structure. On the other hand, the entire SharePoint data, i.e. all site collections, team sites and OneDrive sites backed-up in the storage are archived into data files (.dat). You can set the size limit of a single data file by using the Single archive file size box (Fig. 7.). If the limit is exceeded, the archive job will create another data file. The minimum size of a SharePoint archive is 1 GB.
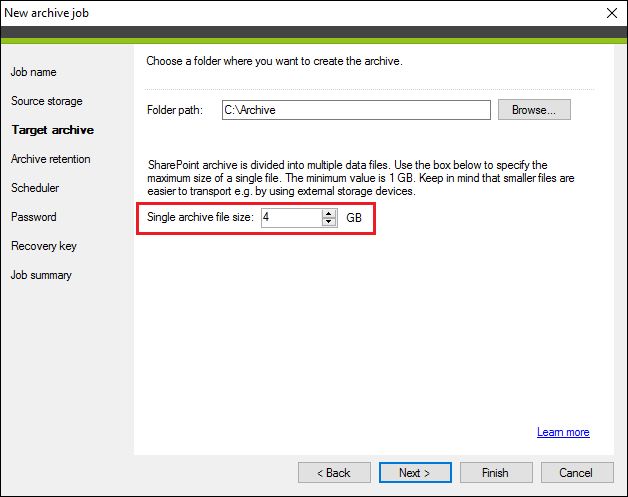
Fig. 7. Dividing SharePoint archive into smaller data files.
Important
We recommend dividing a SharePoint archive into smaller files. This may prove useful when you decide to move the archive to another location at later time, especially by using external storage devices (e.g. USB flash drives, optical discs, etc.).
When you create an archive with CodeTwo Backup, the specified target location will contain both the storage data and certain configuration files. Be sure not to delete the configuration files because they ensure the proper operation of CodeTwo Backup. For example, ArchiveOwner.xml prevents a user from reusing a location which already contains an archive. Otherwise the archive (and consequently data) would become corrupted.
If you intend to archive your storage on a network drive, make sure CodeTwo Backup has all the necessary permissions to that location. Learn more
Archive retention
In this step (Fig. 8.), you can take advantage of one of the data retention policies used in CodeTwo Backup. You can:
- decide how many archives created by this job should be kept in the specified location by selecting the Keep the last [#] archives checkbox,
- specify what action the program will take in the event there is not enough space to create a new archive:
- Delete the oldest archives – the program will delete as many old archives as necessary to create a new archive
- Do nothing – the program will not delete any old archives nor create new ones.
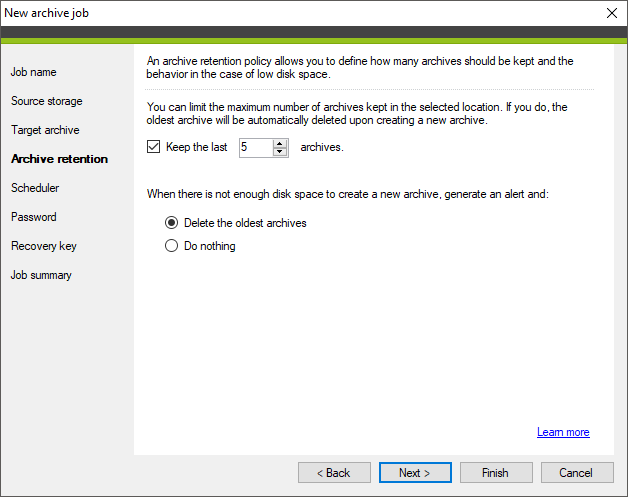
Fig. 8. Data retention policy for archives.
Important
Since external drives may not always be available for the Backup Service, the archive retention policy is not constantly running in the background. Retention policy for the archive is checked and executed only when the archive job is started. We recommend configuring the scheduler so that archiving starts automatically at specified times.
Scheduler
The built-in scheduler can be used to start the archive jobs automatically and to set regular intervals for the program to archive the selected storage, for example twice a week, every other Sunday, once per quarter, and so on.
To begin configuring the scheduler, select the Enable scheduler checkbox. Choose the Recurrence option (Fig. 9.) that matches the intervals at which you want to create a new archive for the storage:
- Daily – if you want the program to create a new archive every day, every couple of days or only on weekdays.
- Weekly – if the program should archive the storage on specific days of the week only. Here you can also indicate the number of weeks that need to pass between each archive job.
- Monthly – in case you don't need to archive your storage very often. This option lets you select specific months and days of the month on which the archiving will take place.
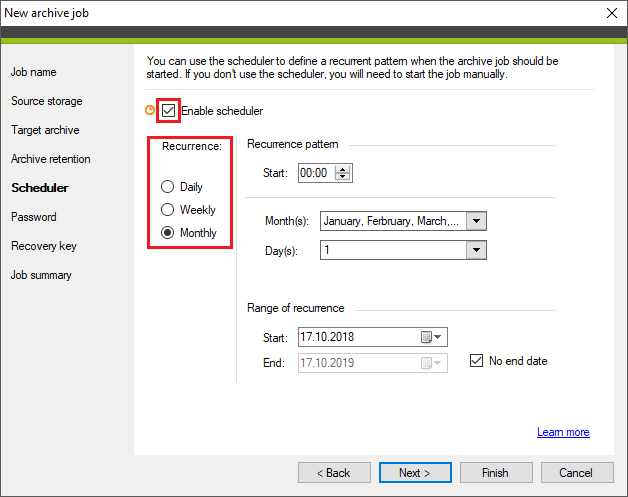
Fig. 9. Configuring the monthly recurrence pattern in the scheduler.
Some additional options allow you to further configure the scheduler:
- In the Recurrence pattern section, by using the 24-hour clock, select or enter the precise hour when the archive job should be started.
Important
Since archive jobs cannot be interrupted and resumed at a later date, the program allows you only to specify when the job starts, not when it should end.
- In the Range of recurrence section, you can indicate the first and the last day when the archive job is executed. By default, the No end date checkbox is selected. However, in case you don't want to archive a specific storage after a certain date, clear that checkbox and select or enter the end date manually (Fig. 10.).
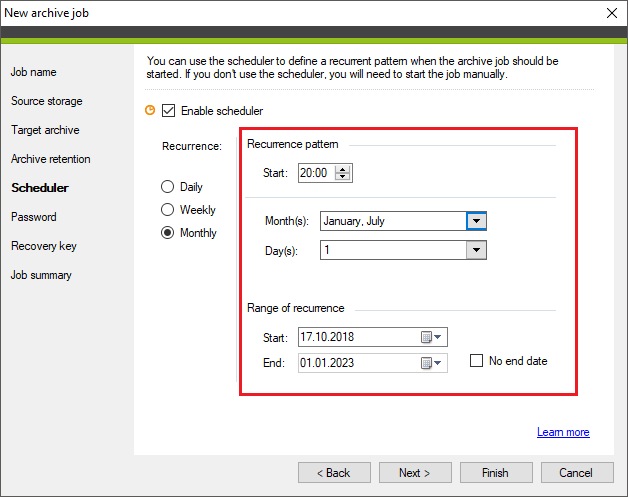
Fig. 10. Additional scheduler options.
According to the configuration demonstrated in Fig. 10. above, the storage will be archived on 1 January and 1 July each year. Archiving will start at 20.00 and continue until finished. The storage will be archived for the last time on 1 January 2023.
Important
Although the scheduler will start the archive job automatically, without any involvement on your behalf, remember that the machine on which the program performs the job must be turned on when the archive job is supposed to run.
Password
You can password protect the archive by selecting the Protect the archive with a password checkbox (Fig. 11.). The program will ask you to provide the specified password if you choose to import the archive back to the program.
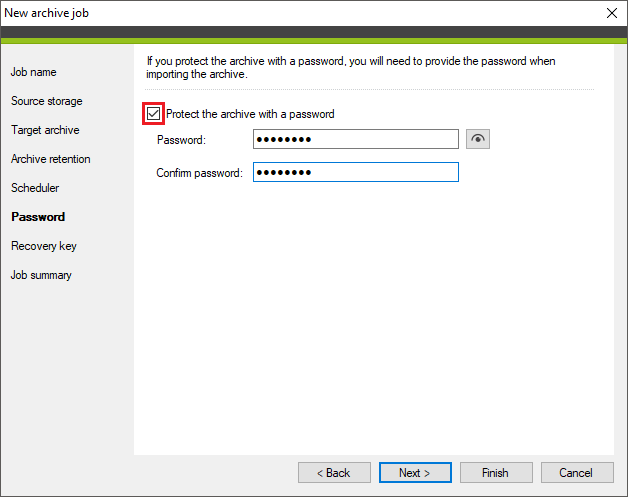
Fig. 11. Protecting the archive with a password.
Recovery key
The program generates a unique recovery key for each archive that allows recovering the encrypted data in case the archive's configuration files get corrupted or you forget the password. You can click the Save button to save a TXT file with the recovery key to a safe location of your choice (Fig. 12.). You can also copy the key directly from the Recovery key field.
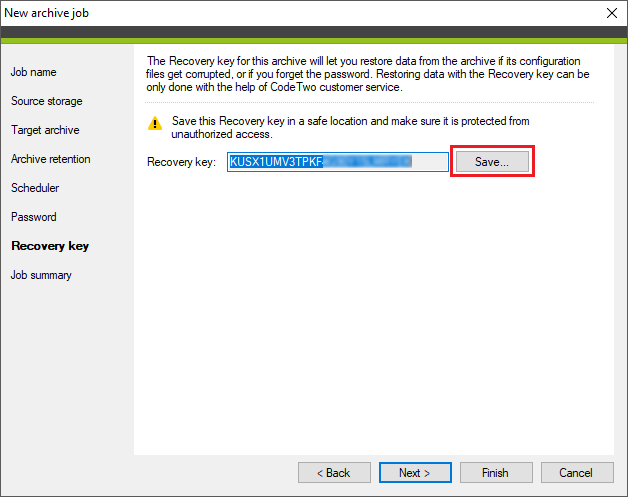
Fig. 12. Saving the recovery key for the archive.
Important
In order to recover the access to your archive, you need to contact CodeTwo Customer Support and provide us with the corresponding recovery key.
Job summary
Here you can verify if you have configured the archive job according to your requirements (Fig. 13.).
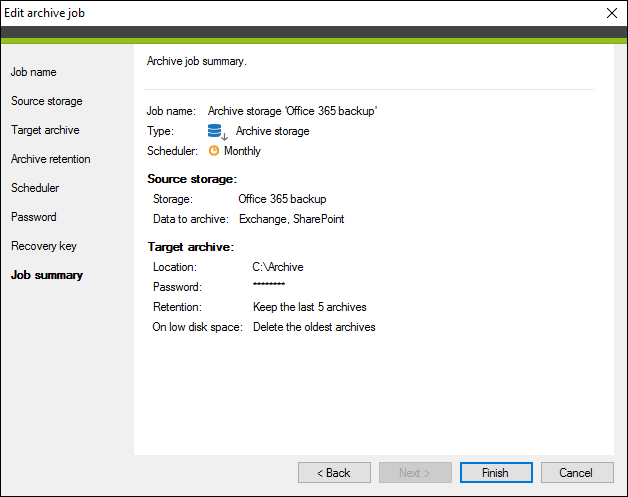
Fig. 13. The summary of the archive job.
In case you want to make any changes, click the name of any of the previous steps of the wizard and adjust your settings accordingly. If everything is correct, click Finish.
If you didn't configure the scheduler, you need to start the job manually. In that case, as soon as you finish the wizard, a pop-up window will appear, allowing you to start the archive job immediately (Fig. 14.). Click Yes to do so.
Fig. 14. A pop-up asking to start the archive job automatically.
Otherwise, use the Start button on the Jobs tab to start the selected job.
Important
Before launching the archive job, make sure that your machine will be turned on long enough for the job to complete. As opposed to backup jobs, the archive job cannot be stopped at some point and resumed later. Once the job starts, it must be completed; otherwise, the archive will become corrupted.