
Simply put, a backup is a full copy of all relevant computer data in the company. However, nowadays the amount of that data is so large that creating backups may take a considerable amount of time. That is why new methods were invented – a differential backup and an incremental backup.
Differential backup
When a company operates on a large amount of data that is constantly growing or changing and does that on a daily basis, a full backup is simply impossible. The process is time-consuming and usually takes a lot of storage space. To address this problem, a differential backup method was invented.
The differential backup takes a copy of all items that were changed since the last full backup.
For example, a full backup was performed on Sunday. Next, on Monday a differential backup job takes a copy of items that were changed or added since Sunday. On Tuesday, the job takes a copy only of the data changed since Sunday, etc.. The cycle is repeated until the next full backup is performed.

Pros:
- The process is much quicker than a full backup since it only takes a copy of what was changed.
- The backup copy itself takes far less storage space than when a full copy is created each day.
Cons:
- The size of the data differences part grows with each cycle. If the cycle is long (e.g. the full backup is performed once a month and the differential is taken every day), at the end of it the size of the archive might be quite big and the process itself pretty lengthy.
Incremental backup
The main difference is that the incremental backup takes a copy of items changed or added since the last incremental backup job. For example, the full backup was performed, as before, on Sunday. On Monday, the incremental job kicks in and takes a snapshot of all data that was changed since Sunday. On Tuesday, the job takes a copy of all changes since Monday, on Wednesday it backs up everything changes since Tuesday and so on.
In other words – the process works in a chain order creating the copy of data modified or added since the last backup job.
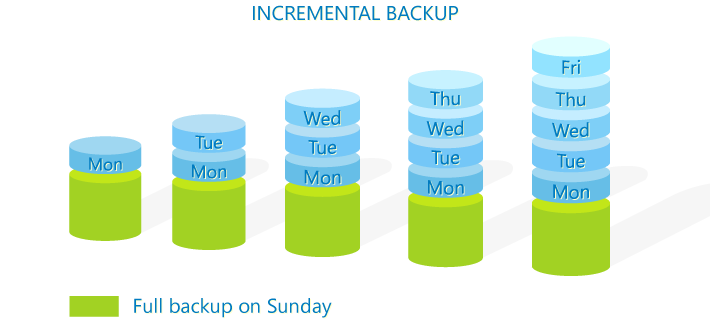
Pros:
- The backup process is even faster than the differential job, not to mention the full backup. It is, in fact, so fast that it can be performed every hour or even minute.
- Each iteration of the backup job copies just the data that was changed. Therefore, only a small amount of storage is required each time.
Cons:
- In some cases, the backup software requires all iterations of the incremental backup for data restoration. If one of the pieces is missing – the restore is impossible.
- The restore process might take some time as the software needs to rebuild data from separate incremental pieces and also the last full backup piece too.
Summary
In the age of the Cloud, it seems that the incremental backup is the best choice – it is fast, pulls down a small amount of data and can be performed even in real time. If you add advanced data versioning and sophisticated recovery processes that rebuild lost information much quicker even without all the incremental pieces, you’ll get a robust tool that has you covered all the time.
CodeTwo Backup for Office 365 is an example of such software – not only does it back up entire mailboxes (all types of items) from Microsoft Office 365, but it also gives you all the benefits of the incremental backup with a pinch of what’s best in the differential type of the process. You can also back up SharePoint Online. Learn more…

Recommended articles

Best explanation ever….the graphics
helped alot
Does the backup capture minor changes on a word document? i.e an incorporation of a sentence?
It depends on the backup solution. When it comes to Office 365, the best way to make sure that all changes are captured (along with the previous document versions) is turning on versioning on a SharePoint site or a OneDrive account.
This is the best explanation one can get on differential and incremental backups…thnx
So far,i have gone and refferred many site,but confused with the Differential and incremental backups…your graphical explanation cleared and gave a detailed picture of the backups..Appreciated
Was confused about this, inspite of visiting a couple of backup sites. Until I saw your graphics. Made it all clear. So helpful I had to comment and say Thanks!!
Please verify that I understand you correctly:
1) In a differential backup there 2 and only 2 files:
(i) the original full backup and
(ii) all of the new changes that have accumulated since the original backup. Each day the old accumulated file is merged in with the previous accumulated data and once the merge has occurred you cannot recover to an earlier day from when the full backup was taken. However, you could recover to any earlier day using an incremental backup since no merge has occurred and each of the files are still distinct.
2) A minor point, but your (incremental backup) reference was to Saturday – shouldn’t that be Sunday?
Hi Dan,
1) Correct. However, a merge does not necessarily have to take place. Oftentimes each day’s backup is saved to a different media or storage – this depends on the software used and specific setup. Still, in case of differential backup, data recovery requires at the most 2 data blocks (1 full backup and 1 differential). So recovery to an earlier day is an option.
2) You’re right :) Will correct this.
Best,
Adam
so incremental backups are faster and requires less disk space compared to differential backups that is slower and requires more space ??
but for recovery ONLY differential is faster the incremental backups ??…
Hi Sam,
In theory – yes. This is because a typical incremental backup saves only “layers”, not recovery-ready data chunks.
– Adam
Clearest explanation I’ve seen of the difference! Much appreciated!
-Susan
Great info!!
Great info, the pictures helped a lot, thank you!
Great information for someone new to the techniques used for backing up a system. I like the quick comparison for easy reference.