The release of Exchange 2013 (and then continued in Exchange 2016) brought us another gem to the precious set of Exchange functionalities, Managed Availability is also known as Active Monitoring or Local Active Monitoring (LAM). Briefly speaking, it is an in-built Exchange monitoring system, which automatically analyses mail server components, and in case of any detected errors or corruptions attempts to fix them (e.g. switches a mailbox database to another server, etc.)
Monitoring Exchange server health and performance using managed availability
The structure of Managed Availability consists of three components:
- Probing
- Monitoring
- Responder
Probing carries out multiple tests on particular mail server services (e.g. client protocols, storage data services responsible for mail flow, data migration or storing). They are carried out on the basis of:
- performance tests – they verify the response value of a particular service according to predefined performance thresholds (e.g. what is the response time of Exchange ActiveSync service),
- health tests – they check the status of a service (active or not responding),
- exception tests – they verify if there are any exceptional events in running services.
The probe configuration cannot be changed. Probing may generate itself an analysis report (e.g. in a form of an entry in event logs) or forward it to the monitoring component. Results of probing can be found in Event Viewer:
Event Viewer -> Applications and Services Logs -> Microsoft -> Exchange -> ActiveMonitoring –ProbeResult
Monitoring is the core component and holds a decisive role in the Managed Availability structure. It is responsible for the data analysis (gathered by the probe component) and determines the action to be taken on a monitored service or an Exchange component, what results in creating notifications in Event Logs, or sending information to the Responder component to execute a command (e.g. a service restart). Monitor surveys the state of a particular Exchange component and may indicate the following states:
- healthy state – when gathered data presents information on no anomalies regarding a monitored Exchange component,
- unhealthy state – when there is a problem concerning a monitored component,
- degraded state – when the monitor indicates the inappropriate behavior of a service within the time limit of 60 seconds,
- disabled state – when a monitor is disabled as a result of administrative actions,
- unavailable state – when a monitor is unable to analyze a component or service,
- repairing state– set up by an administrator when taking action of repairing a component.
A responder is responsible for taking actions on components analyzed by the monitoring component. Such actions include: a service or server restart, entries in event logs, IIS reset, switching of a mailbox to a different database or databases to a different server, turning a service offline or online what may result in rejection or acceptance of client requests by a service.
The physical structure
In a strictly technical sense Managed Availability is based on two processes:
- msexchangehmworker.exe – the worker process that performs tasks;
- msexchangehmhost.exe (Exchange Health Manager Service) – it manages worker processes.
The second process (msexchangehwhost.exe) is more important, if it goes down, the whole Managed Availability component will also go down. The screenshot below presents both processes in Task Manager:
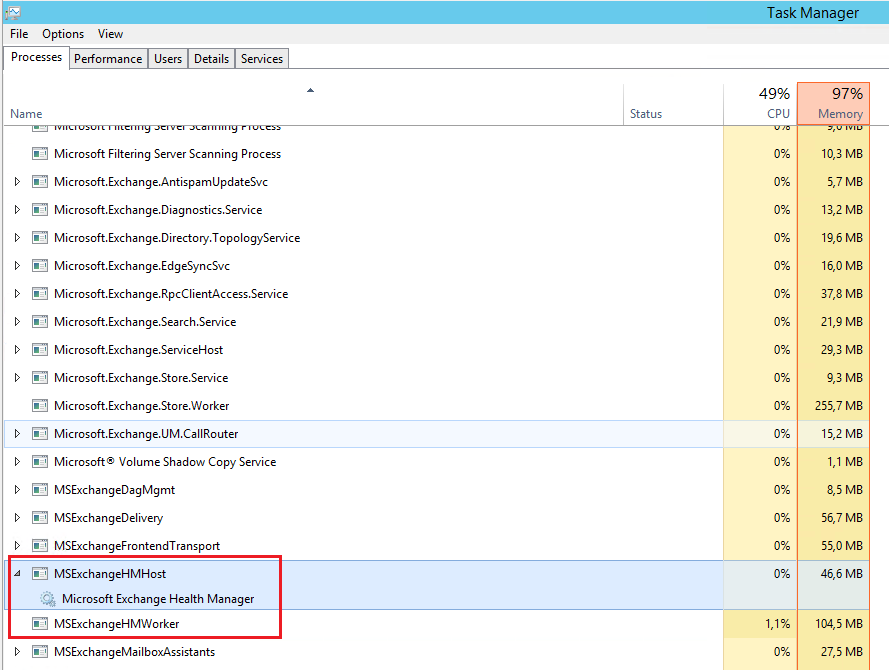
Microsoft doesn’t recommend to turn off any of the Managed Availability components, as it may limit the availability of some elements or affect the whole Exchange 2013/2016 server system. However, there may be a situation that we would like to turn off one of the Managed Availability’s functionalities (e.g. in case that we may suspect that it somehow affects performance and stability of our server). We shouldn’t do it by terminating the Exchange Health Manager Service, but by using the cmdlet called Set-ServerComponentState. For example, to turn off the monitoring feature in Managed Availability, you need to execute the command below:
Set-ServerComponentState -Identity <server_name> -Component Monitoring -Requester Functional -State Inactive
Overrides
As it was mentioned before, the Monitoring component analyzes data gathered during the process of probing. The analysis is based on the comparison of the gathered data results with the predefined thresholds (of certain service checks), what demarks the line between correct or incorrect service behaviors. In case a particular component is recognized as working improperly on the basis of analysis, an appropriate log is recorded in event logs, or a specific action is forwarded to Responder, which attempts to reclaim healthy state of a malfunctioned service. However, there is a possibility to change the predefined thresholds and actions that are sent to responder. We can set values that would fit to our Exchange 2013/2016 environment. The changed values are called Overrides. For example, Cumulative Update installation on the Exchange Server may cause that during probing some services will be incorrectly informing about their current state. Usually, the simplest way to reclaim the proper state of services probing is to restart all monitored services. In this case setting non-standard Override values will restart services when the monitoring component receives information on their improper behavior.
Override values can be set globally for the entire Exchange organization, or locally for a single server. The local override configuration is held in Windows registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\ExchangeServer\v15\ActiveMonitoring\Overrides\
The global override configuration can be found in Active Directory:
CN=Overrides,CN=Monitoring Settings,CN=FM,CN=Microsoft Exchange,CN=Services,CN=Configuration,DC=Example,DC=com
Whether we want to configure overrides on a global or local level, we should use two following cmdlets:
Add-GlobalMonitoringOverride
Add-ServerMonitoringOverride
Log entries
Apart from its basic function of repairing Exchange services, Managed Availability also holds (in registries) logs of probing, monitoring and responder actions. These registries can be found here:
Event Viewer -> Applications and Services Logs -> Microsoft -> Exchange -> Active Monitoring
Event Viewer -> Applications and Services Logs -> Microsoft -> Exchange -> Managed Availability

In ActiveMonitoring, we can find information on probes, monitors and responders configuration, and also results of their activity. Managed Availability holds information about all undertaken repair attempts by this component.
Health Mailboxes
In Exchange 2013/2016, Managed Availability uses so-called Health Mailboxes in order to carry out simulations of users’ actions like sending or receiving messages. Each Active Directory account is associated with these mailboxes. Health Mailboxes implementation has been evolving together with Exchange 2013. Before Cumulative Update 6, there was only one Health Mailbox installed for each database and Client Access Server (CAS). The appearance of Cumulative Update 6 caused that for one database installed on a Mailbox Server there is one Health Mailbox, however, for each Client Server, there are now 10 Health Mailboxes. These mailboxes are kept in the Active Directory container:

In order to display Health Mailboxes in PowerShell, type in the following cmdlet:
Get-mailbox -monitoring | ft name,database

Health Mailbox is a simple mailbox which is associated with an Active Directory user. The display name of a user with associated Health Mailbox that belongs to CAS server:
HealthMailbox-CAS_server_name-consecutive_mailbox_number_within_range_001-010
The screenshot below illustrates an example:

The display name for an Active Directory user with a Health Mailbox associated with a database:
HealthMailbox-server_name_MBX-data_base_name
An example:

In everyday work with Health Mailboxes, there may be two scenarios that would require administrator’s intervention. The first scenario is a corrupted Health Mailbox. It may appear when a database associated with this mailbox is deleted by an administrator, and a user account that refers to such mailbox becomes “orphaned” due to no connection to any object. The best solution is to delete this orphaned account in Active Directory and to restart the Health Manager service.
The second scenario requiring administrator’s attention is a lockout on users Active Directory accounts associated with Health Mailboxes. Whenever an account is locked out, Managed Availability is not able to perform any tests which involve simulations of Exchange users’ actions. A lockout is a result of Password and Account Lockout Policies of an organization and is put on accounts associated with Health Mailboxes installed in Monitoring Mailboxes container. Passwords to these accounts are changed by Health Mailbox Worker and consist of 128-digit-length signs, which in some cases may not fulfill passwords policy, what will result in lockouts of these accounts (accordingly with Account Lockout Policies). That is why Microsoft recommends not to include any accounts (contained in Monitoring Mailbox) in passwords policies. What’s more, it is better not to:
- move users from Monitoring Mailboxes to other containers or organizational units,
- change account properties in Monitoring Mailboxes,
- disable accounts (in Monitoring Mailboxes) in organizations’ Passwords and Account Lockout Policies,
- change inheritance on AD objects,
- move Health Mailboxes between databases,
- put Health Mailboxes in quotes
- in the case of retention policies, delete data in Health Mailboxes before at least 30 days.
The usage of Managed Availability
Type in the following command in Exchange Management Shell (EMS) to verify the status of particular components in Exchange organizations:
Get-HealthReport –Identity Exchange_server_name

As you can observe in the screenshot below, Get-HealthReport displays the status of some of the HealthSets. A single health set is a list of probes, monitors, and responders, organized into a logical set which addresses a particular service or component in the Exchange Server.
In order to show all health sets with the Unhealthy status, execute the following command:
Get-HealthReport -Identity server_name | Where-Object {$_.AlertValue -eq 'Unhealthy'}
The displayed HealthSet called MailboxTransport is shown as Unhealthy. We want to check which one of the monitors reports this status using the command below:
Get-ServerHealth -Identity server_name –HealthSet healthSet_name

The monitor called Mapi.Submit.Monitor is the one responsible for the status of the health set which refers to MailboxTransport.
To verify the configuration of Mapi.Submit.Monitor, we should display records placed in event logs called ActiveMonitoring/MonitorDefinition. We may look for this data through events logs graphical interface or just simply use the following command (recommended):
(Get-WinEvent -ComputerName server_name -LogName Microsoft-Exchange-ActiveMonitoring/MonitorDefinition | % {[XML]$_.toXml()}).event.userData.eventXml | ? {$_.Name -eq " monitor_name"}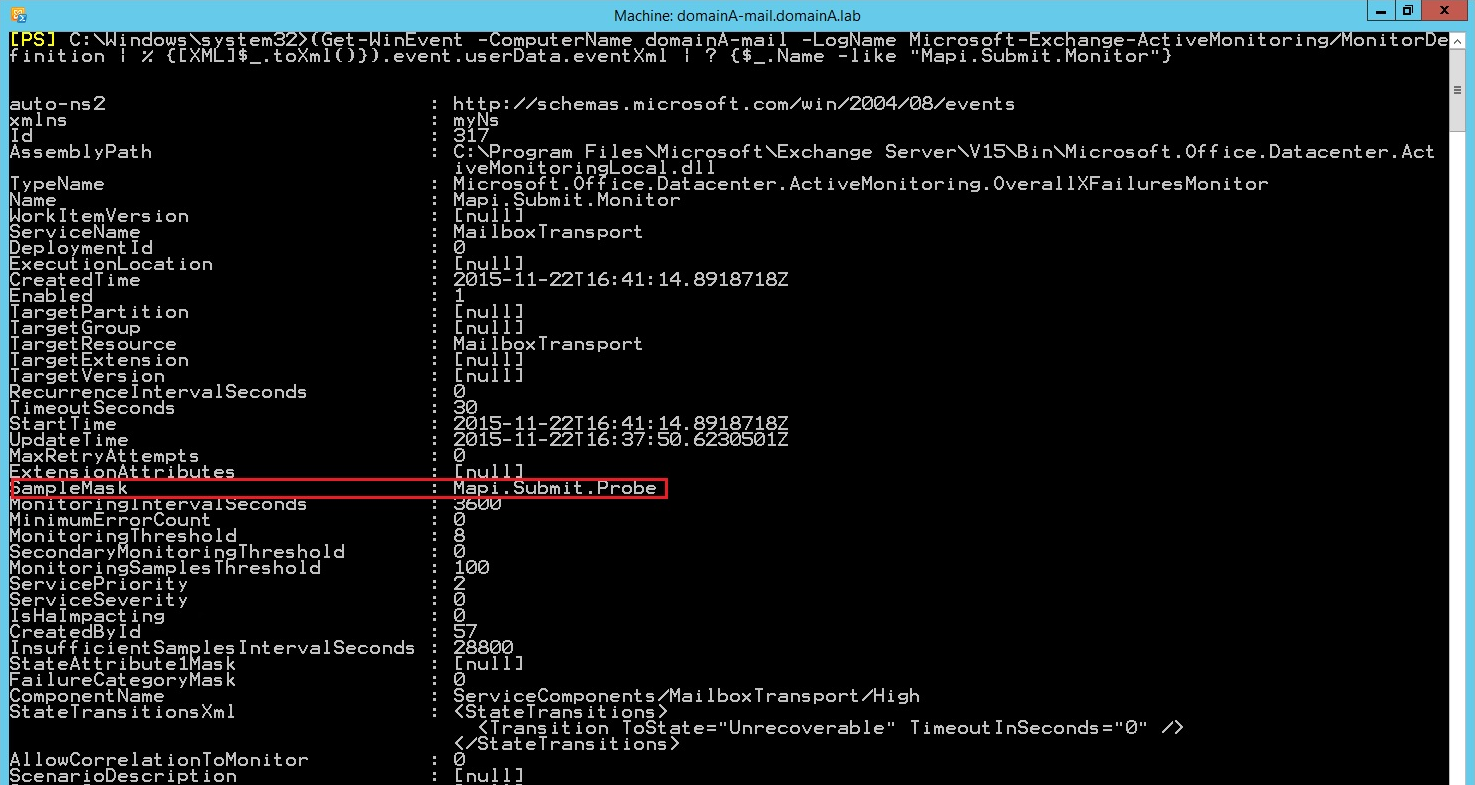
Now we want to check which probe feeds the data into this monitor, to do it we should explore the value of the property called SampleMask. In this case, it is Mapi.Submit.Probe. Next, using the event logs we extract all error logs concerning this particular probe (Mail.Submit.Probe). To achieve this we will use this cmdlet:
$errRecords = (Get-WinEvent -ComputerName domainA-mail -LogName Microsoft-Exchange-ActiveMonitoring/ProbeResult -FilterXPath "*[UserData[EventXML[ResultName='Name/ResourceType'][ResultType='4']]]" | % {[XML]$_.toXml()}).event.userData.eventXmlWe will need Name/ResourceType to the above command. Let’s use:
Get-MonitoringItemIdentity -Identity HealthSet_name -server server_name | select HealthSetName,Name,TargetResource,ItemType

The Get-MonitoringItemIdentity cmdlet allows displaying probes, monitors, and responders associated to a particular health set.
The given screenshot proves that the Name/ResourceType format will become Mapi.Submit.Probe as this probe is not associated with any ResourceType. Therefore, the cmdlet that gathers all error logs from event logs connected with Mapi.Submit.Probe will look like this:
$errRecords = (Get-WinEvent -ComputerName domainA-mail -LogName Microsoft-Exchange-ActiveMonitoring/ProbeResult -FilterXPath "*[UserData[EventXML[ResultName='Mapi.Submit.Probe'][ResultType='4']]]" | % {[XML]$_.toXml()}).event.userData.eventXmlIn order to display the error that caused the TransportMailbox health set is Unhealthy, we should filter the $errRecords with the following cmdlet:
$errRecords | select -Property *time,result*,error*,*context

The above screenshot informs that issues are caused by the delays between the Store and Submission components during the test sending of a message.
Let’s check what is the repair method undertaken by Managed Availability. It is important to check which responder is connected with Mapi.Submit.Monitor. In this case, let’s use the cmdlet:
(Get-WinEvent –ComputerName server_name -LogName Microsoft-Exchange-ActiveMonitoring/ResponderDefinition | % {[xml]$_.toXml()}).event.userData.eventXml | ? {$_.AlertMask -like “*monitor_name*”} | fl Name,AlertMask,EscalationSubject,EscalationMessage,UpdateTime
The responder we were looking for is Mapi.Submit.EscalateResponder as suggested by the screenshot above. This type of responder (Escalate) doesn’t make Managed Availability undertake any automatic repairs but is responsible for log notifications in event logs.
The bottom line
Managed Availability is a powerful component that ensures automatic monitoring, appropriate log entries and repairing of improperly working components and services in Exchange 2013/2016. After an installation of the Exchange Server, Managed Availability doesn’t require any configuration to work. However, there are situations which require administrators to change the default settings in order to neutralize the improper reporting and automatic attempts to repair services and components which work properly. Managed Availability processes a huge amount of data what makes it hard for an administrator to extract specific information. Such analysis of data helps in better understanding of monitoring processes, what they consist of, and most importantly what to do when Exchange 2013/2016 starts to work improperly.
Suggested reading:

Recommended articles


Technical and explanatory summary information for Exchange healthcheck.