Additional configuration information
CodeTwo Office 365 Migration offers additional options that improve the migration process and let you take control of the mailbox items that will be migrated. These options are available as steps in the migration job wizard or the server connection wizard.
To access the migration job wizard, click Edit on the program's ribbon.
To access the server connection wizard, go to Dashboard and click the cogwheel button located in the upper-right corner of the Defined source/target server connections cards.
Read on to learn about each of these steps. In our video tutorial below, you can also find a description of the Time filter, Folder filter, and Advanced settings steps.
Source mailboxes
The Source mailboxes step allows you to decide which mailboxes should and should not be migrated, using different built-in filters (Fig. 1.). Migration is possible only for mailboxes located within the domain (and its subdomains) under which the program is running.
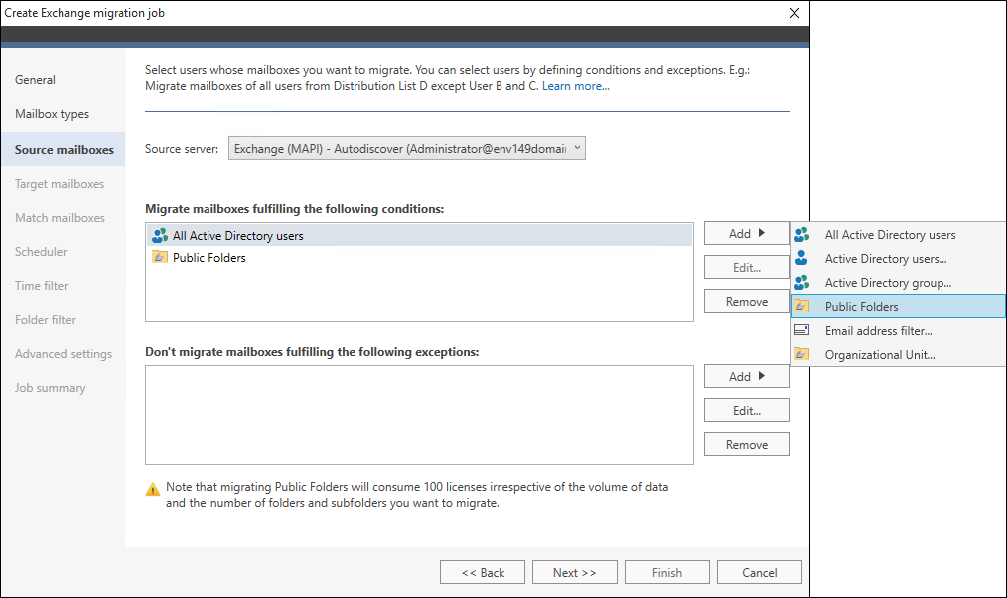
Fig. 1. Setting up mailboxes conditions.
Every filter can be used either as a condition which includes the mailboxes or as an exception that excludes them. You can, for example, set the program to migrate all the users from an Organizational Unit or exclude a user group from migration. The available filters are:
- All Active Directory users (default setting) – all the users who have a mailbox.
- Public Folders (default setting) – all public folders. Be aware that the program automatically consumes 100 licenses for public folders migration.
- Active Directory users – chosen Active Directory user or users. If a user has no active mailbox, the program will not allow you to add such a user.
- Active Directory group – all members of an Active Directory group. The program will automatically add only those members who have active mailboxes. If you add a new user to a group, once a migration job involving the group has started, you will need to restart the program’s Administration Panel to refresh group membership information and make the user’s mailbox appear on the source mailboxes list.
- Email address filter – all the users whose email addresses match a defined filter.
Tip
You can use the asterisk (*) sign to list mailboxes whose email addresses match a pattern. For example, *@my-own-company.com will include all the users located under the my-own-company.com domain. You can use several patterns at a time. Simply separate different patterns with the semicolon (;) sign. The example below will include all the users from my-own-company.com and my-own-company.chicago.com.
*@my-own-company.com; *@my-own-company.chicago.com - Organizational Unit – all members of an Active Directory Organizational Unit. Just like with options above, the program automatically adds only members with an active mailbox.
Warning
Please note that the program will include only users that are actually located within the Organizational Unit.
Let us say, you have a Group One located in Miami OU. Group One contains users from both Miami OU and Chicago OU. In such a scenario the program will migrate only those users, who actually exist in the Miami OU.
Time filter
In the Time filter step of the migration job wizard, you can choose which items will be included in the migration process based on their age (modification date). This option is mainly used for staged migrations. The time filter determines the age of an item depending on the item type. The list below shows which properties are taken into account when defining the item’s age:
- Contacts – Last Modified Date,
- Calendars – End Date,
- Emails – Received Date, then Sent Date, and then Created Date (if the program cannot find the Received Date property, it searches for Sent Date, and so on),
- Tasks – Due Date or, if this property is missing, Last Modified Date,
- Notes – Last Modified Date,
- Journal – End Date.
There are three options to choose from (Fig. 2.):
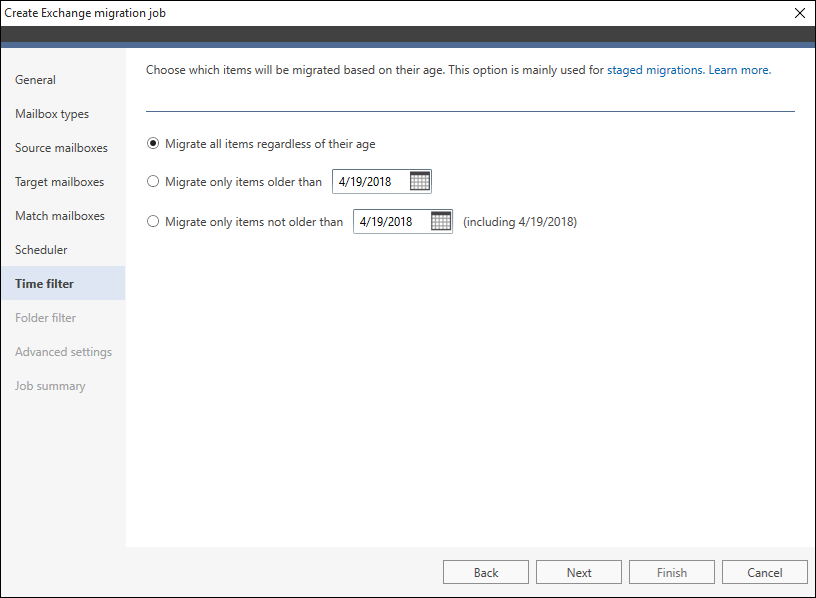
Fig. 2. Options available in the Time filter step of the migration job wizard.
- Migrate all items regardless of their age – choose this option to migrate every mailbox item.
- Migrate only items older than [exact date] – choose this option to migrate only the items that were modified prior to the selected date. For example, if you select 1 December 2016, every item modified before that date will be migrated.
- Migrate only items not older than [exact date] – choose this option to migrate only those items that were modified on and after the specified date. If you now select 1 December 2016, every item modified on 1 December 2016 up to now will be migrated.
Note that when you decide to migrate items based on their age, the Override the time filter for contact items checkbox (marked by default) will appear (Fig. 3.). Clear this checkbox to apply your custom settings also to contact items.
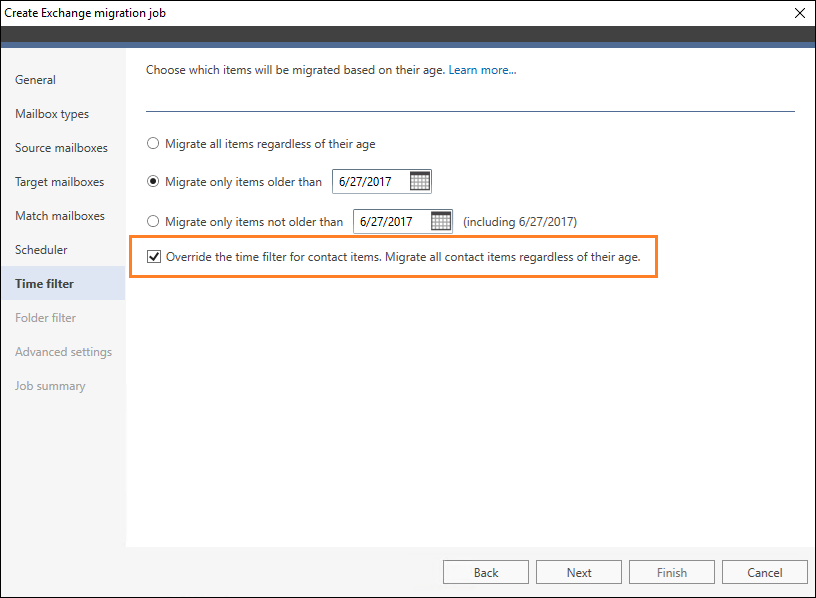
Fig. 3. Configuring the time filter to migrate all contact items regardless of their age.
Folder filter
The Folder filter step lets you decide which folder types will be included in the migration process. This feature is helpful, e.g. if some folders contain a lot of useless items. Such folders can be excluded from the migration to shorten the migration time and save network bandwidth.
Warning
If you are configuring an IMAP job, only mail folders can be chosen. This is due to the limitations of the IMAP protocol.
There are two general types of folders that can be managed using the Folder filter option:
- default folders
- special folders
The table below shows the types of default and special folders that can be included in the migration process depending on the type of the source server chosen in the connection wizard:
| Source server type | Default folders | Special folders |
|---|---|---|
|
|
|
Important
Please note that the contents of Suggested Contacts/Recipient Cache (Contacts type) and RSS (Emails type) special folders will always be migrated, as long as they exist in the mailbox and the corresponding folder type is checked.
In turn, however, some special folders are not available for migration at all - those are i.e. Sync Issues or folders created when putting a mailbox on litigation hold.
*If you choose to migrate Deleted items, the program will migrate only the items present in this folder. Items deleted from this folder (that can be recovered in a particular mailbox by using the Recover Deleted Items feature in Outlook) will not be migrated.
As some of the folders' types are unchecked by default, it means that they will not be included in the migration process unless you mark the corresponding checkbox.
The Junk folder (special folder) is the only folder type that is excluded from migration by default (Fig. 4.). Mark the corresponding checkbox if you want to include this folder in your migration job.
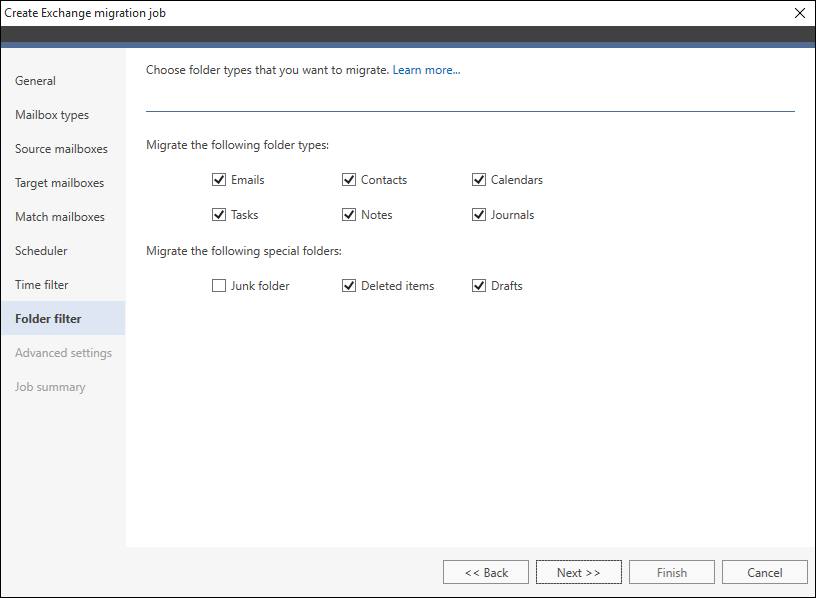
Fig. 4. Folders that are excluded from migration by default while configuring the migration job.
The Advanced settings step of the migration job wizard (Fig. 5.) lets you:
- set the maximum number of concurrent mailbox migrations. In other words, you can decide how many mailboxes should be migrated at the same time;
- set the maximum size of an item to be migrated.
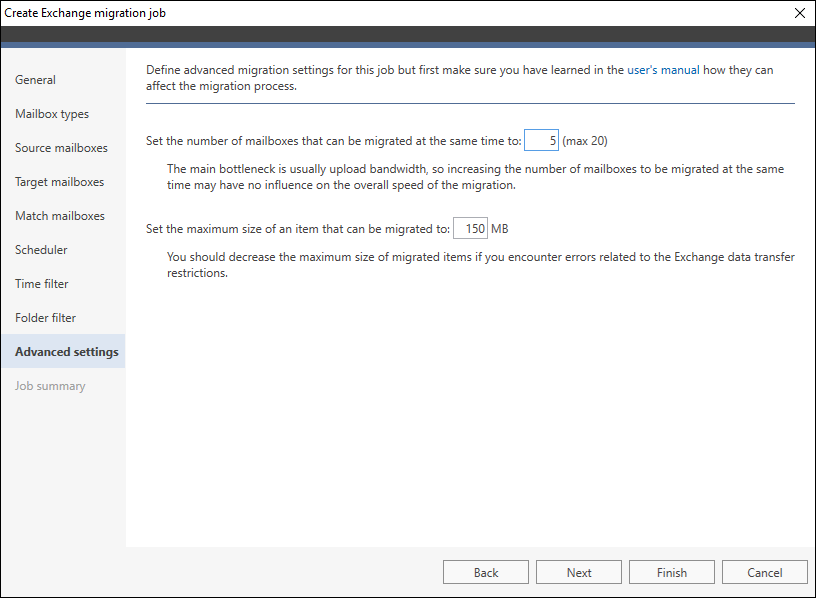
Fig. 5. Advanced settings (Exchange migration via MAPI).
The number of concurrent migrations is limited to 20 to maintain the performance of the migration process. The actual value in this field depends on the job type. For Exchange jobs, the number of simultaneous migration connections is equal to the number of logical processors in your machine. For IMAP jobs, the recommended value is 2. The main bottleneck is usually the upload bandwidth, and in such a case increasing the number of concurrent connections will not directly improve the migration process and may even cause performance loss. You can modify this value on your own, but if you’re configuring a migration job for the first time, we strongly recommend that you leave the default settings. Change the default settings only after you’ve run the migration for some time and found out that the process is too slow. In this case, see also the migration speed article before making any changes.
The option to change the maximum size of migrated items may be used to improve the migration stability. In the case of Exchange source connections via MAPI, you should decrease the maximum size of migrated items if you encounter errors related to insufficient system memory. In the case of other connections, you should decrease the maximum size of migrated items if you encounter errors related to the Exchange data transfer restrictions.
Throttling
This step allows you to address data transfer limits that may be imposed by the IMAP server. Often, free email providers (e.g. Google) limit how much data can be downloaded via IMAP per hour, day, etc. The number of IMAP sessions per mailbox can be limited too. Those limits, or the so-called throttling, differ between email service providers, so it is impossible to configure the software in one universal way. If you are about to download a significant amount of data via IMAP (a few or more gigabytes), you should check the help website of your mail provider before starting the migration to find out if there are any IMAP throttling policies set server-side. If yes, configure the software to avoid reaching those limits.
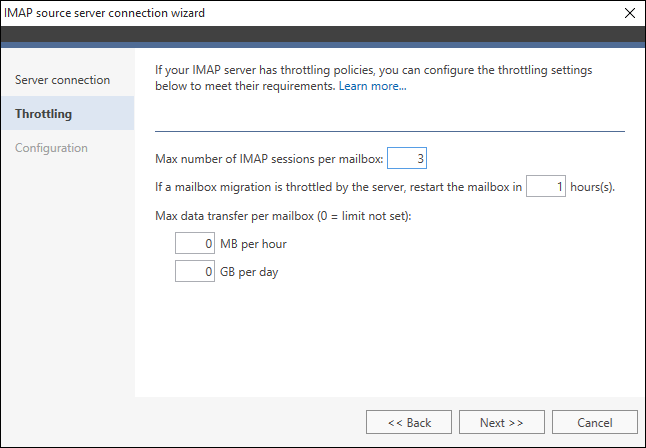
Fig. 6. IMAP throttling settings.
You can adjust the following options:
- Max number of IMAP sessions per mailbox – by default, the value is set to 3. This option is limiting the maximum number of concurrent IMAP connections to a single mailbox.
- If a mailbox migration is throttled by the server, restart the mailbox in [h] – by default, the value is set to 1 hour. If the migration of a mailbox has been suspended due to the throttling policy, this value specifies how many hours the application should wait before attempting to continue the migration.
Additionally, by using Max data transfer per mailbox, you can define how many megabytes per hour and gigabyte per day can be migrated. After exceeding those limits, the migration of a mailbox will be suspended and the program will move on to migrating other mailboxes. The default value is 0 (zero) which means there is no limit.
Importing CSV file
Watch our video tutorial to see the entire migration process when using a CSV file or check out detailed instructions below.
In several parts of CodeTwo Office 365 Migration, you can import data from a CSV file. The data in the CSV file can be arranged in any order and separated with any delimiter, because the program allows you to easily distinguish and map data from the file to specific fields. Depending on the purpose for which you are importing the file, different fields are used:
- Listing source mailboxes (used in the IMAP migration job wizard)
- Matching mailboxes (used in the Match mailboxes window)
- Importing mailbox pair (used when migrating mailboxes by using a CSV file, e.g. for migrations from hosted Exchange servers)
Refer to the table below to see what type of data can be provided in the CSV file (green ticks) and which fields are required.
| Field name | Listing source mailboxes |
Matching mailboxes |
Importing mailbox pairs |
|---|---|---|---|
|
Email address/Login or |
|
||
| Password/App password 1) |
|
||
| First Name or Source mailbox First Name |
|
|
|
| Last Name or Source mailbox Last Name |
|
|
|
| Display Name |
|
|
|
| Source mailbox Type |
|
|
|
| Target mailbox Type |
|
|
|
| Source mailbox email address/login |
|
|
|
| Target mailbox email address |
|
|
|
| Source mailbox ID 5) |
|
||
| Target mailbox ID 6) |
|
* Required field
1) For IMAP migrations from Gmail or Google Workspace, you need to use app password instead of a regular Google password. Learn more
2) It is required to map either the Source mailbox email address field or both the Source mailbox First Name and Source mailbox Last Name fields.
3) It is required if you've chosen to migrate both primary and archive mailboxes (learn more). Allowed values: Primary or Archive.
4) It is required if you've chosen to migrate archive mailboxes only or both primary and archive mailboxes (learn more). Allowed values: Primary or Archive.
5) This data field uses the ExternalDirectoryObjectId property value in Office 365 or ExchangeGuid in on-premises Exchange.
6) This data field uses the ExternalDirectoryObjectId property value in Office 365.
Based on this table, when listing source mailboxes from an IMAP server, you need to provide at least the login (or email address) and the password of the mailbox.
Let's assume that you have an existing IMAP user whose mailbox data you want import in the Source server step of the IMAP migration job wizard:
Display Name: David Black
Email address: [email protected]
Password/App password: vHS3dsb5sFg3Dda2
To prepare a valid CSV file in a text editor (e.g. Notepad) containing all the data, the file should consist of the following line:
"[email protected]";"vHS3dsb5sFg3Dda2";"David";"Black";"David Black"
Once you select a CSV file in the program, a window opens (Fig. 7.), where you can map the data from the file to mailbox fields used by the program.
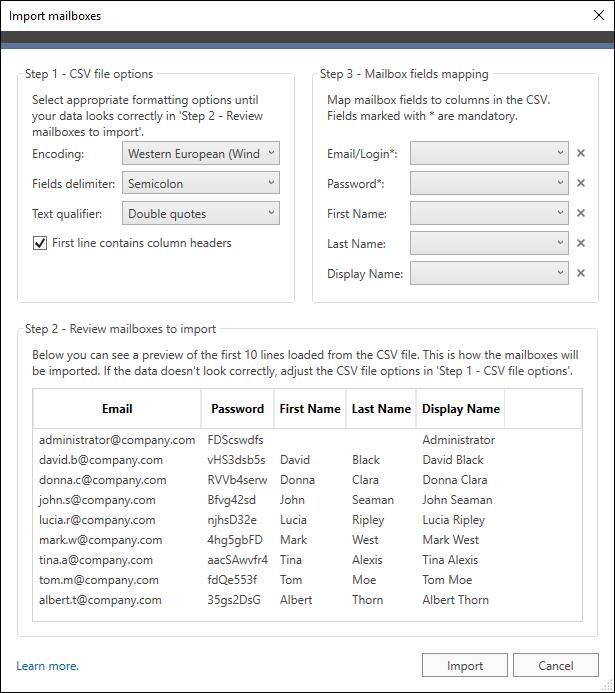
Fig. 7. Importing source mailboxes from a CSV file.
Mapping is done in three steps:
- Step 1 – CSV file options – where you define how the program should read the CSV file to get all data correctly. The following options can be adjusted:
- Encoding – determines what encoding should be used while reading the file.
- Fields delimiter – specifies a character that separates data fields in the CSV file. Usually a semicolon (;) or a comma (,) is used, but other separators may also be used, e.g. tab or space. There is also an option to select a custom character.
- Text qualifier – lets you choose a pair of characters that indicate the beginning and end of a single field (e.g. "David Black"). The program accepts files that use double quotes ("), single quotes ('') or no qualifiers at all.
In addition, if the first row of the CSV file contains column headers, you can select the First line contains column headers checkbox to tell the program to ignore that row.
- Step 2 – Review your data – where you can preview the data imported from the CSV file. This allows you to verify if correct options were selected in Step 1. The imported data should be arranged in columns. Keep in mind that the program always displays the first 10 rows from the imported file.
- Step 3 – Mailbox fields mapping – where you can define which field used by the program should correspond to which column from the imported file (e.g. Login = Column 1). The table above shows which fields are required.
After all steps are completed correctly, use the Import button to start importing the data into the program. Once the import is complete, you should see a summary of all the potential errors that might have been encountered.
Below are some of the examples on how to prepare a CSV file, perform mapping in the program, and troubleshoot common problems.
- Example 1: Importing a CSV file created in Notepad
- Example 2: Importing a CSV file created in Excel
- Example 3: Importing a CSV file exported from the Exchange admin center
Example 1: Importing a CSV file created in Notepad
You want to migrate 3 mailboxes from an IMAP server to your Office 365 tenant using CodeTwo software. For that purpose, you created a CSV file in Notepad (or similar text editor) that contains the data required by the program. The file has the following entries (Fig. 8.):
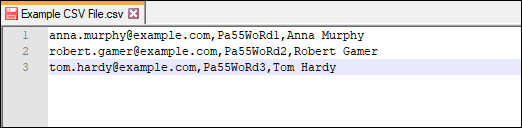
Fig. 8. An example of a valid CSV file created in a text editor.
When you import the file to the program, the data shown in Step 2 looks as follows (Fig. 9.):
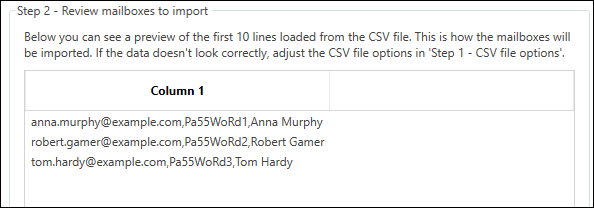
Fig. 9. Data imported from a CSV to the program before applying correct formatting settings.
To make it look correctly, in Step 1, you need to select Comma as fields delimiter, and None as text qualified. Next, in Step 3, map Email/Login to Column 1, Password to Column 2, and Display Name to Column 3 (the last one is optional). The correct settings are shown in Fig. 10.
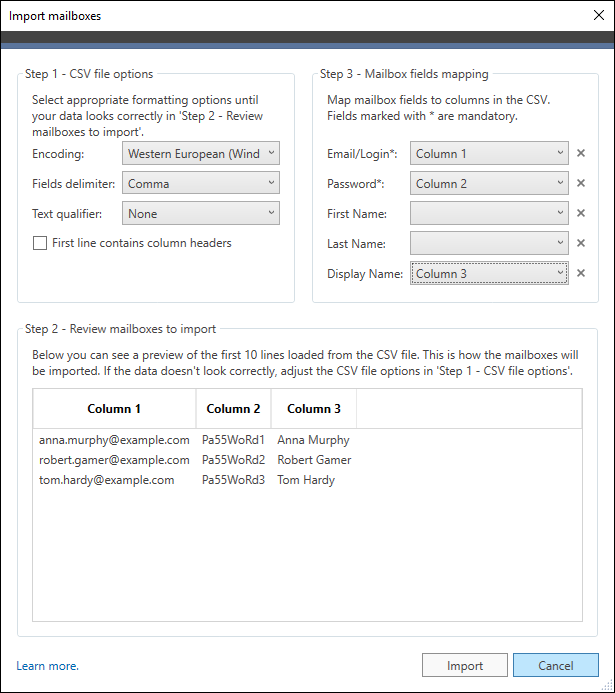
Fig. 10. Correctly configured CSV file import settings.
Once done, click Import to import the data from the file to the program.
Example 2: Importing a CSV file created in Excel
You prepared the following entries in an Excel file (Fig. 11.):
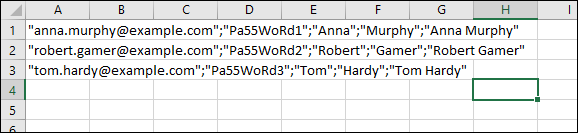
Fig. 11. An example of a badly formatted CSV file created in Excel.
After importing the file to the program and selecting Semicolon and Double quotes options in Step 1, all data is still contained in a single column, as shown in Fig. 12. below.

Fig. 12. A badly formatted CSV file imported to CodeTwo migration software.
To see what went wrong, try opening the CSV file in a text editor, e.g. Notepad. You will see that Excel added some additional quotation marks while saving the file as CSV:
"""[email protected]"";""Pa55WoRd1"";""Anna"";""Murphy"";""Anna Murphy""" """[email protected]"";""Pa55WoRd2"";""Robert"";""Gamer"";""Robert Gamer""" """[email protected]"";""Pa55WoRd3"";""Tom"";""Hardy"";""Tom Hardy"""
If you want to use Excel to create a valid CSV file, either remove the double quotation marks from the file shown in Fig. 11. or simply put the data into separate columns, without using any delimiters or qualifiers (Fig. 13.). This can be done easily by using the Text to Columns feature found on the Data tab in Excel.
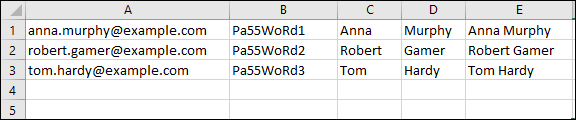
Fig. 13. An example of a valid CSV file created in Excel.
The CSV file created in this way can now be imported to your CodeTwo software using the same settings as in this example.
Example 3: Importing a CSV file exported from the Exchange admin center
You’ve exported a list of mailboxes from the Exchange admin center (either in Office 365 or in the on-premises Exchange server) to a CSV file (Fig. 14.), e.g. by following this article.
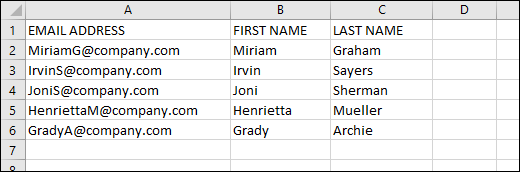
Fig. 14. A CSV file exported from the Exchange admin center.
You now want to use this file in CodeTwo migration software to match source and target mailboxes. To do it, you need to update your CSV file with additional information, as shown below.
(Optional) If you've chosen to migrate archive mailboxes or both primary and archive mailboxes in the Mailbox types step of the wizard (learn more), you need to first add one column (archive mailbox migration) or two columns (primary & archive mailbox migration) where you'll specify the mailbox type (see Fig. 15.). The only permissible values are Primary and Archive. If you migrate both mailbox types, you also need to duplicate the entries for each user, typing Primary for the first entry and Archive for the other one, as shown in Fig. 15. That’s because an archive mailbox is always a duplicate of the primary one, sharing the same mailbox ID and other mandatory values to be included in the CSV file.
Important
If an archive mailbox is not enabled for a given user in your source environment, add just a single entry for them, leaving the cell in the TARGET MAILBOX TYPE column empty or (optionally) filled with Primary.
Keep in mind that to successfully migrate archive mailboxes, you need to first enable them for selected or all users in the target environment, as shown in this article.
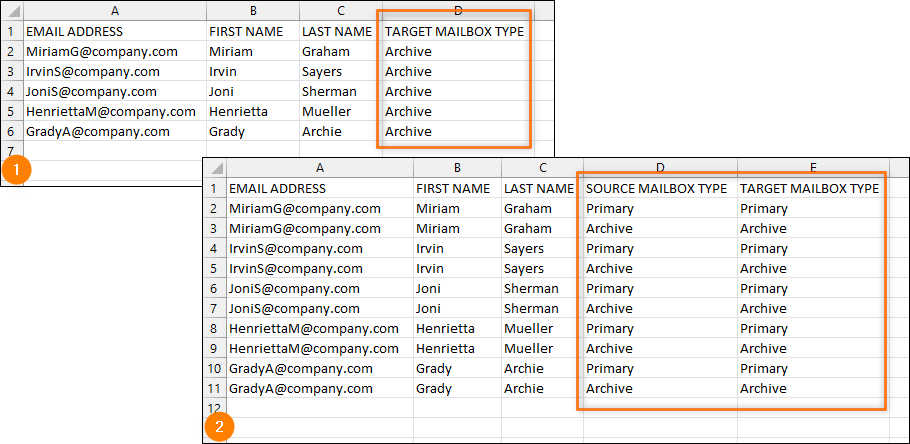
Fig. 15. Adding information about mailbox type – archive mailbox migration (1) and both primary and archive mailbox migration (2).
Next, you need to include another column that will contain an email address of the target mailbox (Fig. 16.).
Info
If you duplicated your source environment data to be able to migrate both primary and archive mailboxes for your users (as shown above), you also need to duplicate email addresses of the target mailboxes.
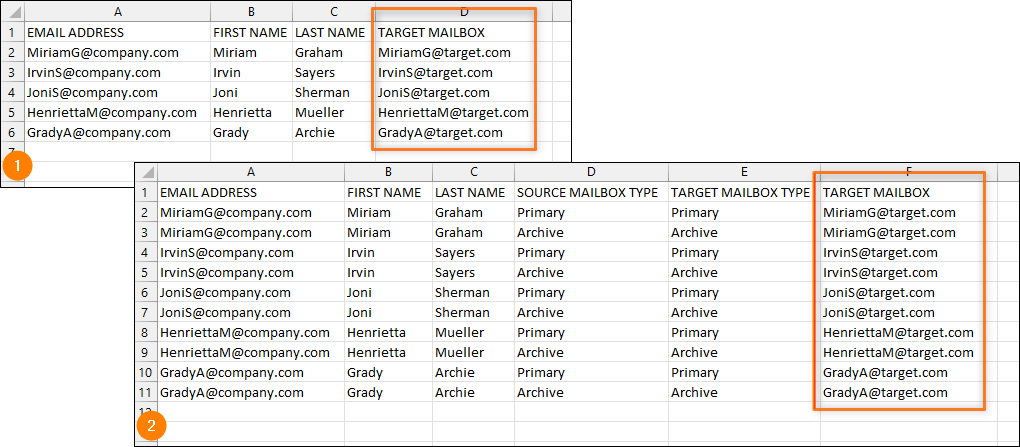
Fig. 16. Adding target mailboxes details – migration job includes only primary (1) or both primary and archive mailboxes (2).
After doing so, import the file to the program. In Step 1 of the Import matched mailboxes window, select Tab as a field delimiter, since the data fields in a CSV file exported from the Exchange admin center are separated with tabs. In addition, you also need to select the First line contains column headers option. In Step 3, map the fields used by the program with appropriate column headers. The correct settings are shown in Fig. 17. below.
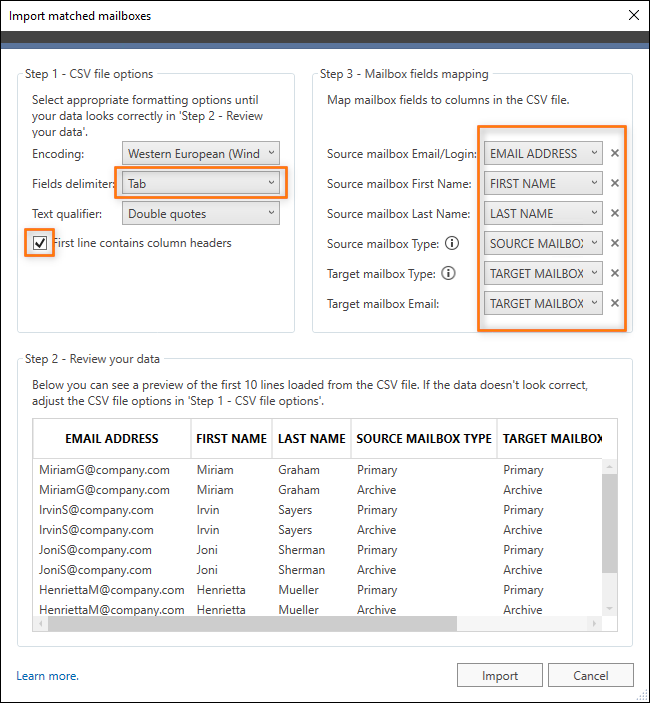
Fig. 17. Formatting options used for a CSV file exported from the Exchange admin center.
Once done, click the Import button to import the data to the program.
Troubleshooting errors that occur while importing mailbox pairs from a CSV file
There are seven types of errors that can occur in the Mailboxes step of the migration job wizard during the import of a CSV file - four of them concern mandatory data fields, while the remining three are related to defining a mailbox type.
Errors related to missing mandatory information
These errors will occur if mandatory information used to correctly identify a mailbox is not provided in the CSV file (Fig. 18.). The mandatory data fields are as follows: Source mailbox email address, Source mailbox ID, Target mailbox email address and Target mailbox ID. If any of these fields are missing from the CSV file or contain incorrect values, the migration will not be possible between a given mailbox pair.
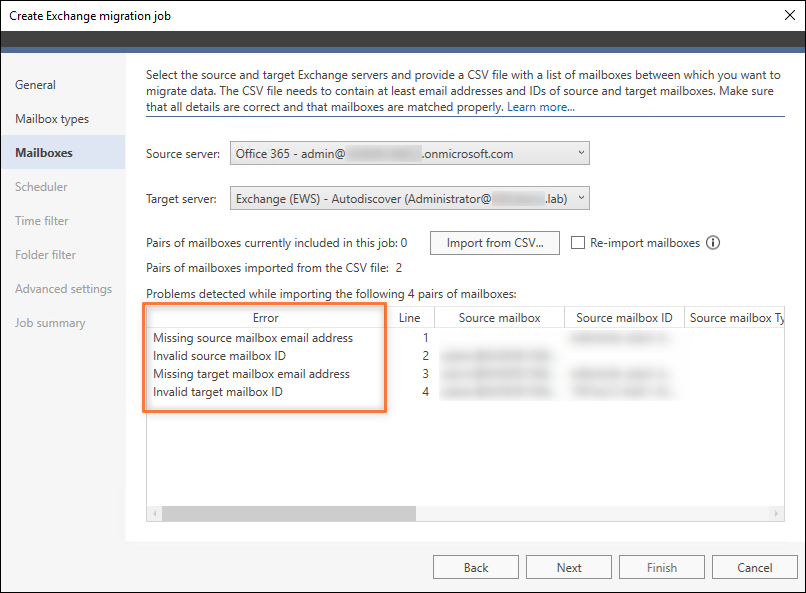
Fig. 18. Errors that might occur when mandatory mailbox information is missing.
- Missing source mailbox email address - the information in the Source mailbox field is missing.
- Invalid source mailbox ID - the information in the Source mailbox ID field is missing.
In case of these two errors, you need to fix your CSV file. To do so, open it in a suitable editor and enter the missing information. Then, import the file again. If you do not fix the file, these incomplete entries will be omitted and the mailboxes to which they apply will not be migrated. Select the Re-import mailboxes checkbox if you want to remove the previously imported mailbox pairs and only add mailbox pairs from the most recent file. Learn more
- Missing target mailbox email address - the information in the Target mailbox field is missing.
- Invalid target mailbox ID - the information in the Target mailbox ID field is missing.
In case of these two errors, you can either fix your CSV file, as described above, or continue configuring your migration job. If you decide to finish the wizard without fixing the CSV file, you can then go to the Jobs tab, select your job, and find the mailboxes that caused the error. They can be found for example by looking at the information in the Target user mailbox column, which will display Click to match target (Fig. 19.). Then, follow the instructions in this article to automatically match target mailboxes or create target mailboxes if they do not exist.
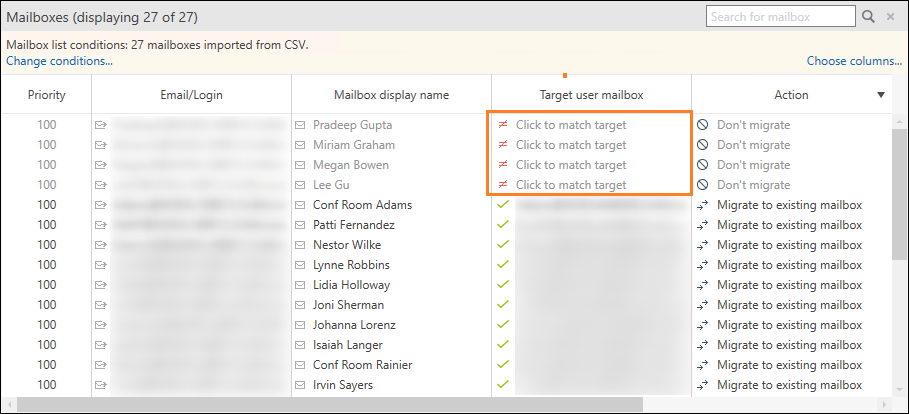
Fig. 19. Source mailboxes without a target mailbox assigned, as displayed on the Jobs tab.
Errors related to defining a mailbox type
These errors might occur (Fig. 20.) when you fail to provide correct value in the Source mailbox Type or Target mailbox Type field. For example, if you've chosen to include archive mailboxes in your CSV-based migration job by selecting an appropriate option in this step of the wizard.
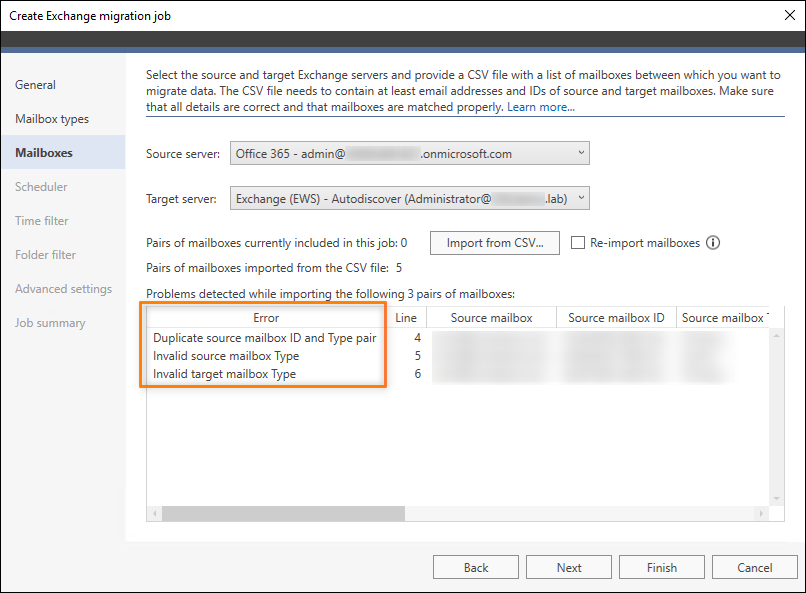
Fig. 20. Errors related to wrong information about mailbox type.
- Invalid source mailbox Type - the value entered into the Source mailbox Type field is incorrect.
- Invalid target mailbox Type - the value entered into the Target mailbox Type field is incorrect.
Primary and Archive are the only values that can be used in the above mentioned fields. You will get this error if you type anything else in the columns of your CSV file that are mapped to these fields in our software. To be able to proceed with your migration job, you need to fix your CSV file by opening it in a suitable editor and typing the permissible values. Then, you should import the file again.
- Duplicate source mailbox ID and Type pair - there are at least two mailboxes that share the same values for both ID and type in your CSV file.
The mailboxes imported from a CSV file must have unique combinations of values in the Source mailbox ID and Source mailbox Type fields. To fix the error, you need to open your CSV file in a suitable editor, remove or modify the items in the CSV file that share the same values in the two columns mapped to the two above-mentioned fields, and import the file again. Otherwise, only the first of the duplicates will be migrated.
Tip
To avoid this error type when you prepare a CSV file for a migration job that involves both primary and archive mailboxes, for a single user, you need to:
- use the same source mailbox ID for their primary mailbox and archive mailbox, BUT
- enter a different mailbox type (Primary and Archive respectively).
A similar situation (but in the context of mailbox matching) has been shown in Fig. 15. (learn more).