This manual refers to an old version of CodeTwo Backup. Go here if you use the latest version.
Program's components
The architecture of CodeTwo Backup resembles a client-server model. There are two main components of the software: the Backup Service and the Administration Panel. Both of them have to be installed, but serve different purposes and run independently from each other. There is also another service called the Indexer that allows you to easily browse and search the backed-up data.
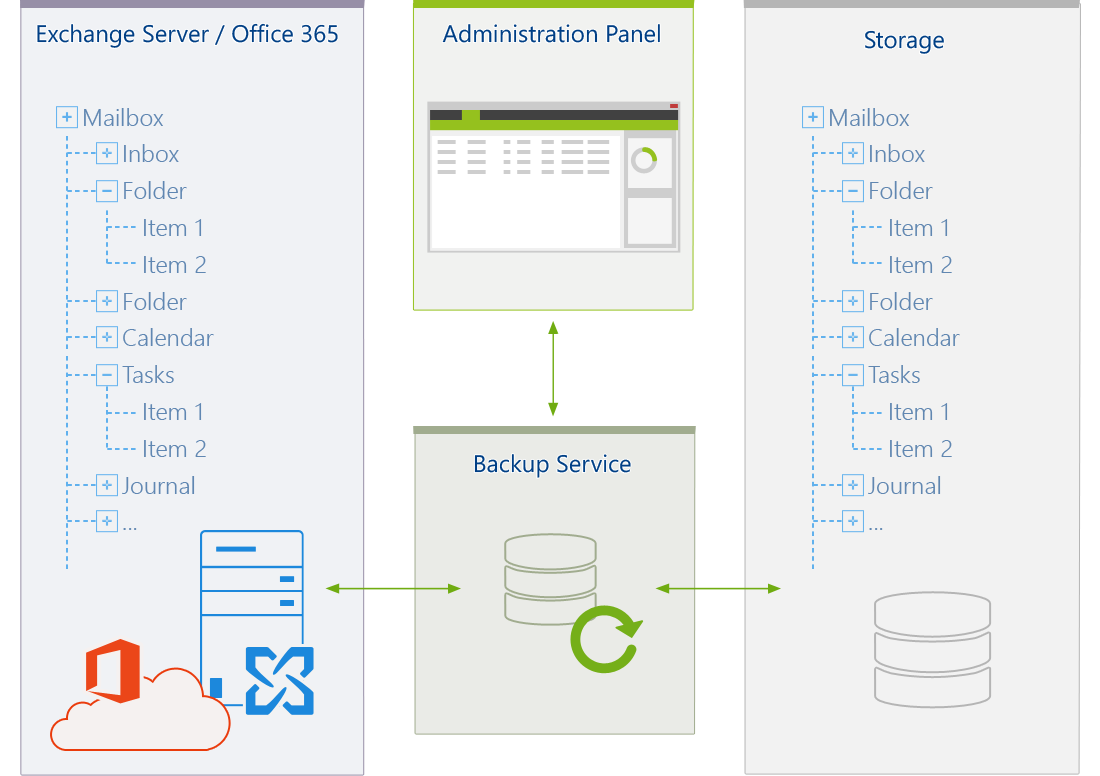
Fig. 1. CodeTwo Backup architecture for Exchange data.
Backup Service
The CodeTwo Backup Service is the core component of the software. It is responsible for managing the backup and restore jobs, saving and accessing the data in the storage, and running retention policy processes as well as archive, PST archive, and import jobs. The Backup Service runs seamlessly in the background as a Windows service and features a built-in scheduler which supervises job schedules. This means the Backup Service will automatically execute any jobs predefined by the user, and this person does not have to monitor and manage various job stages. As the service runs under the Local System account, the admin does not even have to be logged on to the machine. It is enough to just keep the machine running and the Backup Service will do the rest.
Administration Panel
The Administration Panel allows the user to configure the Backup Service: create jobs, configure the scheduler, set up server connections or start one-time jobs. Moreover, the Backup Service status can be checked: if any issues arise, the Dashboard of the Administration Panel will display alerts. A user can review them and access the software's log files for further investigation. Furthermore, the storages can be created, mounted/unmounted, archived or imported, and the backed-up data can be can be previewed. The Administration Panel can be used by anyone who has access to the server, but there are built-in security options available to ensure the safety of backup data and processes.
The Indexer
An additional component of the software - the Indexer - is a service that runs in the background and indexes keywords of the backed-up data to a separate index database in each store. The purpose of this process is to catalog the content of all items. This is required for the search feature to work. The Indexer starts to work when the backup process is finished. Therefore, you might notice that even though a job is not running anymore, the software still uses some resources - this is the Indexer working on the recently backed-up data. Please note that a separate instance of Indexer is started per each storage. That means that if you start multiple backup jobs (each configured to back up your data to a separate storage), this may consume a considerable amount of resources - most of all, your hard drive usage might be affected. Be aware that the Indexer runs completely independently: a user is not able to interfere with the work of the indexing service, customize or disable it, etc. So if you know beforehand that you will be configuring lots of jobs and saving data to many storages, it might be wise to install the software and store data on a dedicated machine with high-speed drives/disks. You may also try to optimize your drive's workload by lowering the number of storages for your jobs.
In this article